At a glance
If you are weighing build vs buy enterprise RAG, the weekend tutorial path is seductive: LangChain or LlamaIndex for orchestration, Pinecone or Weaviate for vectors, a chunking script, and a Slack bot wrapper. What the tutorial does not show is the eighteen months after launch — OAuth token refresh for Salesforce, citation hydration that survives legal review, multihop queries across deals and support tickets, and agents that write insights back to CRM without breaking field validation.
Gyri is an agentic knowledge base built for GTM operators who need more than document chat:
- Federated GTM stack — one query across CRM, email, Slack, and docs, not siloed app-by-app search
- Cited AI answers — synthesis with source citations your reps can trust in customer-facing work
- Context that compounds — a knowledge graph and persisted insights, not chat that resets every session
- MCP agents that write back — Claude, Cursor, and custom agents that update CRM, create insights, and run workflows
A home-built pipeline deserves credit where it earns it: full control over embedding models, chunking research, custom rerankers, and air-gapped architectures you already operate. For a narrow corpus — 500 PDFs in one SharePoint site — DIY RAG works. The knowledge base build or buy decision shifts when GTM asks relational questions across CRM, email, Slack, and support in month six.
For adjacent evaluations, see Gyri vs ChatGPT Enterprise and RAG vs knowledge graph for companies.
Quick comparison
Legend: ✅ Strong · ⚠️ Partial · ❌ Not native
| Capability | Gyri | Custom RAG |
|---|---|---|
| Federation & search | ||
| Federated search (CRM + comms + docs) | near-real-time sync across Gmail, Slack, Drive, CR… | You build connectors |
| Keyword + semantic hybrid retrieval | exact-match keyword search plus semantic graph ret… | You tune retrieval |
| Real-time / webhook ingestion | webhooks and scheduled crawlers keep records current | Your pipelines |
| Custom API / HTTP connectors | workspace HTTP endpoints and bridge mutations | Full control |
| Knowledge graph & multihop | ||
| Typed entity knowledge graph | people, deals, emails, threads linked as graph nodes | If you build it |
| Multihop GraphQL queries | traverse deal → contact → email → ticket in one qu… | If you build it |
| Cross-source correlation | joins timing, people, and language across systems | Engineering-heavy |
| Cited answers & trust | ||
| Cited AI answer synthesis | claim-level citations to source records | Your citation layer |
| Audit trail / citation chains | full citation chain back to original sources | Your logging |
| Insight persistence & memory | ||
| Compounding insights | structured insights accumulate across sessions | Your schema |
| Institutional memory | decisions and context survive employee turnover | Your design |
| Version history on knowledge | insight and record versioning | Your design |
| MCP agents & delivery | ||
| MCP-native agent endpoint | one MCP surface for Claude, Cursor, custom agents | You expose MCP |
| Workspace-scoped auth & audit | per-workspace permissions and tool visibility | Your auth |
| Write-back workflows | ||
| CRM / record write-back | agents update custom records and CRM fields | If you build it |
| Agent-driven workflow automation | stored agents and workspace workflows on rails | Full control |
| GTM workflows | ||
| Pre-call briefs | cited briefs from CRM + email + support | 12-month build |
| Competitive intelligence | competitor mentions across Slack and email, persis… | Custom jobs |
| Churn / CS health signals | support themes joined to account health in CRM | Custom joins |
| Sales enablement / battlecards | live cited synthesis vs static wiki cards | Custom UI |
| Implementation & TCO | ||
| Time to value (GTM teams) | Days–weeks · pre-built connectors and graph schema | Months to quarters |
| Connector long-tail maintenance | Managed · Gyri maintains federation layer | You own forever |
| Pricing transparency | Published · see gyri.io/get-started | Infra + headcount |
What a custom RAG stack actually delivers
The familiar DIY shape works for doc search: ingest and chunk documents, embed into a vector index, retrieve top-k chunks, generate with an LLM, ship via FastAPI or Slack bot. Custom RAG earns its place when the mandate is narrow and engineering wants full control:
- Embedding and retrieval control — choose models, chunk sizes, rerankers, and air-gapped deployment without vendor constraints.
- Sealed corpora — internal policy search, a single SharePoint library, or developer docs with no CRM federation requirement.
- Bespoke automation — write-back logic tied to internal systems only your team understands.
- Pedagogical experimentation — learning retrieval mechanics with no immediate GTM production requirements.
The gap appears when GTM asks questions that span systems: "Which enterprise deals mentioned our competitor in email after a support escalation?" Vector search alone cannot traverse deal → contact → email thread → ticket. That is where langchain enterprise projects stall between demo and production.
Federation & search
Gyri federates operational GTM systems into one queryable layer; a custom RAG stack federates only what your engineering team has time to connect. Both can ingest documents, but Gyri joins CRM records, email threads, Slack messages, and documents as linked entities; a typical LangChain + Pinecone pipeline returns top-k chunks from whatever sources you have indexed.
The connector long tail
Most knowledge base build or buy debates underestimate connectors. Phase 1 (Drive, Notion) is easy. Phase 2 (HubSpot stages, Zendesk themes, Gmail threads linked to opportunities) explodes scope — each source has different auth, pagination, delta sync, and schema. Phase 3 (internal Postgres, GraphQL APIs, Airtable) requires another ingest job per system.
Gyri's federated search connects SaaS and custom records in one graph. Keyword federators search live HTTP APIs; bridges traverse from a custom customer_job row to HubSpot company to Gmail thread in one query. The long tail is a permanent tax on engineering attention.
Pre-call research illustrates the divide. A rep preparing for a renewal needs deal stage in CRM, the champion's last emails, open support tickets, and Slack threads where pricing was discussed. A custom stack surfaces each source's best-matching chunks if you built those connectors; Gyri assembles a cited brief from hydrated records across systems in one response.
Custom RAG wins when the mandate is full control over a sealed corpus with no SaaS federation requirement. Gyri wins when GTM teams need operational joins across CRM, comms, and support without a warehouse project first.
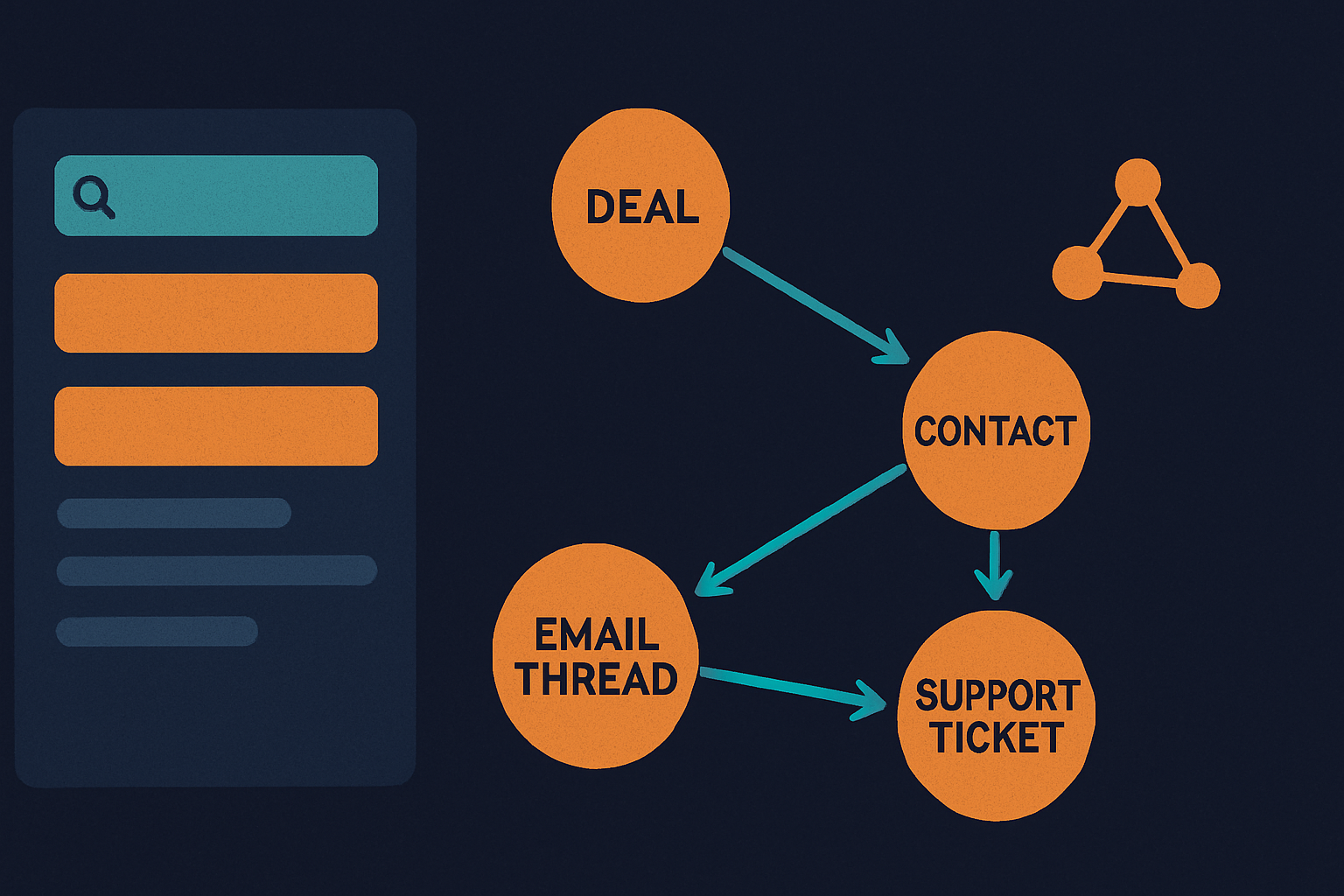
Knowledge graph & multihop
A custom RAG stack retrieves semantically similar chunks; Gyri traverses a typed knowledge graph with multihop GraphQL. Pure vector RAG answers "What text is semantically nearby?" GTM questions are structural: stalled deals with P1 tickets, competitive mentions correlated with losses, email commitments missing from CRM. These require multihop traversal — see RAG vs knowledge graph.
Gyri models connected sources as typed graph nodes — people, deals, emails, Slack threads, support tickets, insights — linked through explicit bridges. Multihop GraphQL traverses deal → contact → email → ticket in one request without maintaining a separate Neo4j cluster.
Concrete multihop questions revenue teams ask:
- "List every Slack mention of Competitor X tied to opportunities in negotiation stage."
- "Which accounts have declining email engagement AND rising support ticket volume in the last 30 days?"
- "Summarize the decision chain for the Acme renewal — who said what, when, across email and Slack?"
Custom RAG accelerates finding chunks that might contain answers. Gyri answers the question directly — with citations to each record in the traversal path.
Graph, citations, write-back
Vector chunks answer similarity; GTM needs graph traversal, hydrated citations, MCP delivery, and write-back — each a separate build on a DIY stack.
Cited answers & trust. Vector RAG returns chunks with footnotes pointing to source files. GTM needs hydrated citations — deal record, email message, support ticket — that managers can click through and compliance can replay. Gyri treats citations as first-class; synthesis outputs carry refs (deal:…, email:…, insight:…) that hydrate through GraphQL. See AI answers with citations.
Insight persistence. Most custom RAG stack projects stop at generation. Gyri stores typed insights in the workspace graph — competitive dossiers, account health narratives, research conclusions that accumulate across agent runs. When an AE departs, Gyri retains the graph of what happened on their accounts. See Institutional memory when employees leave.
MCP agents & write-back. Without MCP, you build separate integrations per agent client. Gyri exposes one workspace-scoped MCP surface: search, GraphQL, insight creation, and connector tools. Agents write back into GTM systems with admin-defined guardrails — creating typed insights, updating custom records, and triggering workspace workflows. See MCP for business agents and Agents that write back.
| Workflow | Custom RAG | Gyri |
|---|---|---|
| Pre-call briefs | Export deal fields and email chunks; miss support context unless built | One cited brief with deal stage, champion engagement, tickets |
| Competitive intel | Keyword-filtered Slack exports to spreadsheets | Federate Slack and email; persist insights linked to accounts |
| Churn / CS signals | Brittle warehouse joins between Zendesk and CRM | Ticket themes joined to account health in near-real time |
| Write-back | Build guardrails: validation, permissions, idempotency, audit | Analyze loss → persist competitive insight → update battlecard |
Custom RAG wins when session-based chat is sufficient and you want full control over agent architecture. Gyri wins when revenue workflows must compound across quarters with cited, auditable synthesis.
Implementation & TCO
The POC cost of custom RAG is deceptively low; the 12-month operating cost is where langchain enterprise projects stall. Build vs buy resolves quickly once you list the connectors, citation requirements, and workflows your GTM team will ask for in month six — not just the demo they applaud in week two.
Hidden build costs nobody puts in the POC budget
- Embedding and reindexing tax — every model upgrade triggers a full reindex across CRM exports, Slack archives, and docs.
- Prompt engineering as permanent headcount — someone becomes the "RAG whisperer" tuning chunk size and guardrails as data shapes change monthly.
- Citation + audit layer — claim-level citation hydration and replayable audit chains: 4–8 weeks of engineering, then ongoing maintenance.
- Graph / multihop queries — deal → contact → email → ticket traversal on a vector-only stack: 8–12+ weeks if attempted at all.
12-month TCO comparison
| Cost line (Year 1) | Custom RAG (LangChain + Pinecone + 3 connectors) | Gyri |
|---|---|---|
| Initial build (eng weeks) | 8–16 weeks (2–3 engineers) | Days–weeks to connect sources |
| Vector DB + LLM inference | $2K–$15K/mo scaling with usage | Included in platform tier |
| Connector maintenance | 0.5–1 FTE ongoing | Platform updates |
| Citation + audit layer | 4–8 weeks build + maintenance | Native |
| Graph / multihop queries | 8–12+ weeks if attempted | Native GraphQL federation |
| GTM time-to-value | Often 6–9 months to trusted workflows | Pre-call briefs, CI, churn signals in weeks |
Gyri publishes pricing paths at gyri.io/get-started. Custom RAG pricing is infra plus headcount — economical when you have dedicated platform engineers and leadership accepts multi-quarter timelines.
Hybrid patterns that work
Buy vs build is rarely binary:
- Gyri as GTM intelligence layer; DIY for domain-specific ML — keep specialized models in-house; let Gyri federate operational context for revenue teams.
- Custom RAG for a sealed corpus; Gyri for operational federation — policy search on internal docs; cited briefs and CRM write-back on live GTM data.
- Build a prototype; buy when adoption criteria hit — validate retrieval mechanics in a POC; deploy Gyri when GTM needs citations, multihop, and MCP agents in production.
The anti-pattern: a production custom RAG stack that grows connector-by-connector until it is an unmaintained internal search product nobody trusts in customer-facing work.
Verdict
Choose Gyri if:
- Revenue, CS, or RevOps teams need cited answers across CRM, email, Slack, and docs — not just document chat.
- You want agents in Cursor and Claude to share one company graph via MCP without N custom APIs.
- Write-back workflows (insights, CRM fields, briefs) matter as much as retrieval.
- Engineering would rather configure workspace types and bridges than maintain OAuth refresh logic for five SaaS products.
- Time-to-value is measured in weeks: pre-call briefs, competitive intel, account health synthesis.
Choose a custom RAG stack if:
- Your use case is narrow and doc-centric — internal policy search, a single SharePoint library, developer docs with no CRM federation.
- You have dedicated platform engineers who want full control over embedding models, chunking research, and custom rerankers — and leadership accepts multi-quarter timelines for citation and graph features.
- Data must stay in a specific air-gapped architecture you already operate, and federation to SaaS is out of scope.
- You are experimenting pedagogically — learning retrieval mechanics — with no immediate GTM production requirements.
Choose a hybrid if:
- You have specialized ML or sealed corpora in-house, but GTM operators still need federated, cited, write-back agents for daily workflows. Let Gyri be the operational layer; keep DIY where you truly have unique advantage.
The build vs buy enterprise RAG question is not really about whether your team can build retrieval. It is about whether you want to own the long tail of connectors, graph semantics, audit trails, and GTM workflows — or buy an agentic knowledge base that ships those layers ready for revenue teams.
If your next step is seeing federated search, cited synthesis, and MCP agents on your actual stack, start your free trial. Bring your messiest cross-system question — deal history, support friction, competitive mentions — and we will show you how an agentic knowledge base answers it with proof.
FAQ
What is the difference between Gyri and Custom RAG?
Custom RAG and Gyri both connect company data to AI, but they optimize for different jobs. Gyri is an agentic knowledge base for GTM teams — federated search, multihop graph queries, cited synthesis, MCP-native agents, and write-back workflows. Custom RAG may excel at its core use case; Gyri is built for revenue and operations teams that need cited, persistent operational intelligence.
When should I choose Gyri over Custom RAG?
Choose Gyri when your buyers are RevOps, Sales, CS, or Enablement; when you need multihop questions across CRM, email, Slack, and support; when citation-auditable synthesis is required; and when MCP agents and write-back workflows must compound institutional memory over quarters.
When should I choose Custom RAG over Gyri?
Choose Custom RAG when its native strengths — full control over embedding models, sealed corpora, or air-gapped architectures — match your primary mandate better than cross-stack GTM intelligence. Many enterprises run DIY RAG for narrow doc search alongside an agentic knowledge base for revenue teams.
Does Gyri integrate with MCP agents like Claude and Cursor?
Yes. Gyri exposes workspace search, graph queries, cited synthesis, and write-back tools via MCP (Model Context Protocol). Agents in Claude Desktop, Cursor, and custom tooling can query federated context without exporting data to a chat window.
Can I try Gyri before committing?
Yes. Gyri offers a free trial at app.gyri.io where teams connect CRM, email, Slack, and docs and see federated search with cited answers in minutes.